AI 기반 RAG 챗봇과 다국어 번역 시스템 – 공공서비스 디지털 전환의 키 인프라로 부상
디지털 전환이 본격화하면서 공공기관의 정보 제공 방식에도 근본적인 혁신이 요구되고 있다. 유앤피플이 출시한 RAG(Retrieval-Augmented Generation) 기반 민원 자동화 챗봇 ‘U-Talk’과 실시간 웹 번역 시스템 ‘U-Lingo’는 이러한 흐름을 정조준한 대표적 사례다. 기술적 기반부터 활용 방식, 디지털 정책과의 접점까지 AI 기술이 공공서비스 혁신의 핵심 자산으로 진화하고 있음을 보여준다.
AI 챗봇의 진화 – 단순 응답을 넘어 ‘맥락 대응형 서비스’로
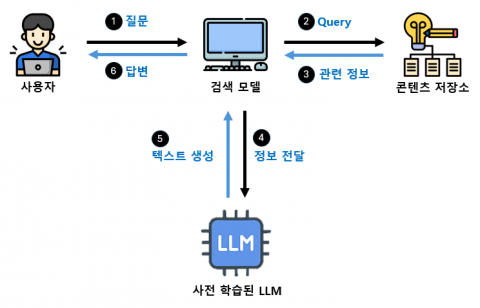
U-Talk은 RAG 아키텍처를 기반으로 기존 단문 응답 중심의 챗봇 방식을 넘어, 문서 검색과 문장 생성을 결합해 정확한 정보 응답과 맥락 이해를 동시에 구현하는 것이 핵심이다. 단순히 FAQ를 따라가는 수준이 아닌, 기관 내부 문서·DB·보도자료·공공 API로부터 정보를 실시간으로 추출하고 이를 자연어로 정리해 제공한다. 특히, 민원 이력과 대화 흐름을 반영한 상담 프로세스 설계는, 공공 민원 시스템에서 사용자의 피로도를 크게 낮추는 경험 설계 방식으로 주목된다.
미국 IRS 상담시스템, 영국 Gov.uk 자동응답 플랫폼 등도 유사한 기술을 채택하고 있으나, 대부분 정형화된 질문에 대한 일회성 응답이 주를 이룬다. 반면 RAG 기반 시스템은 전례 없는 질문에 대해서도 '최적의 대응 자료'를 실시간 구축하여 응답하는 생성형 AI의 넓은 대응 폭을 확보한다.
이런 흐름은 단순 IT 아웃소싱을 넘어, 공공기관 내부 문서 구조의 표준화·디지털화라는 구조변화를 유인한다. 정형 정보뿐 아니라 비정형 민원 내용까지 실시간으로 분류하고 자동화함으로써, 수작업 기반의 민원 처리 체계를 탈피하며 행정 프로세스 전반의 능동화로 확장되는 흐름이다.
공공 웹 번역의 패러다임 전환 – HTML 구조 인식 기반의 번역 자동화
U-Lingo는 단순 텍스트 번역 엔진이 아닌, 웹사이트의 HTML 구조를 인식하고 원본 콘텐츠의 UI를 그대로 유지한 채 다국어 콘텐츠를 생성하는 데에 초점을 맞춘다. 이는 기존의 ‘페이지 별 수작업 번역+개발’ 방식에서 개발자 개입 최소화, 다국어 접근성의 표준화를 확보할 수 있는 구조로 전환한다는 의미다.
특히 기관별 고유 용어(예: 조례명, 부서명, 민원 카테고리)를 학습해 맞춤형 번역을 제공하며, 정책·제도처럼 맥락 중심의 문장을 다루는 공공 부문 특성을 구체적으로 반영한다. 공공기관뿐만 아니라 관광, 의료, 법률 등 다국어 정보 제공이 필수인 산업에서 U-Lingo와 같은 기술 기반 모델은 빠르게 확산될 전망이다.
한국은 UN 전자정부 평가에서 수차례 상위권에 올랐지만, 다국어 정보 제공 비율은 여전히 15% 미만(한국정보화진흥원, 2023)으로 낮은 편이다. 다국어 웹소통은 포용적 기술로서 접근성과 정보 형평성을 개선하는 도구로 재해석되어야 하며, U-Lingo는 이 전환의 일선 사례로 자리매김하고 있다.
AI 기술력과 공공 SI 경험의 접목 – 시장 확산의 기반
유앤피플이 확보한 차별성은 AI 기술 자체보다도 공공 SI 시장에서의 도메인 이해도다. 다수의 공공 CMS 통합 구축 경험은 기관별 문서, 민원 패턴, 보안 요구사항을 정확히 알고 있다는 강점으로 전환된다. 이는 AI 기술의 ‘도입 난이도’ 문제를 낮추고, 고도화된 LLM이나 멀티모달 인터페이스와의 향후 통합도 수월하게 만든다.
공공기관의 기술 검증은 단순한 PoC(Pilot)가 아니라 보안, 접근성, 성능 기준을 모두 통과해야 하는 복합 엔지니어링이다. AI 시스템의 클라우드 배포, DBMS 연동, 운영 독립성, 장애 복구, 고객지원까지 포함한 총괄 운영 역량이 확보되어야 한다. 이 점은 스타트업이나 외산 솔루션이 진입하기 어려운 버티컬 마켓의 실무 구도를 보여준다.
정책 결합을 통한 공공 AI 확산 구조의 설계 필요
GPT API 및 해외 LLM 성공 사례만으로는 한국 공공서비스에 접목시키기 어렵다. 다국어·민원 자동화 시스템이 확산되기 위해서는 데이터 거버넌스, 개인정보 보호, 국산 AI 생태계 육성 정책이 병행되어야 한다. 예산 항목 상 ‘디지털 업무 자동화’ 혹은 ‘공공 다국어 지원’ 같은 명확한 정책 코드화가 필요하며, 이를 통해 예산 수립-검토-납품까지 디지털 행정의 공급 프로세스가 정착될 수 있다.
또한, 기술 형평성 확보를 위해 중소 지자체에도 적용 가능한 경량형 AI 모델, On-premise형 배포 옵션 등을 병행 도입해야 한다. 이는 지역간 디지털 격차를 최소화하고, 궁극적으로 AI 기술의 공공적 가치 실현을 이끄는 구조적 기반이 될 수 있다.
마지막으로, 실무자와 기획자가 기술을 적용할 때는 ▲내부 업무 프로세스의 디지털 단계 구조 파악, ▲정형·비정형 데이터의 통합 구조 마련, ▲도입 AI의 맥락 이해 능력 수준 검증, ▲보안·접근성 요건 명세화, ▲기술 공급사와의 SLA(Service-Level Agreement) 명문화 등이 체크포인트로 작동해야 한다.
유앤피플 사례는 단지 AI 솔루션 도입이 아니라, 기술전환기 공공부문 서비스 체계의 본질적 구조 혁신을 위한 운용 인프라의 재구성으로 해석될 수 있다. 이 흐름은 향후 정책 설계, 기술 개발, 사회적 수용성을 아우르는 AI 거버넌스를 정립하는 출발점이 될 것이다.

